Những nghịch lý về gene người!
Sinh học dường như là một lĩnh vực vẫn còn nhiều bí ẩn đổi với khoa học và gene của loài người cũng vậy, tới thời điểm hiện tại vẫn có những vấn đề mà chúng ta chưa thể giải thích được.
Nghịch lý giá trị C
Great chain of being - Chuỗi tồn tại vĩ đại là một cấu trúc có thứ bậc của mọi vật chất và sự sống. Trong chuỗi sự tồn tại, Thượng đế đứng đầu và có chín cấp độ của thiên thần, dưới các thiên thần là con người và dưới họ là động vật, thực vật và khoáng chất. Do đó, vị trí trong chuỗi càng cao thì càng có nhiều thuộc tính, bao gồm tất cả các thuộc tính của những thứ có vị trí thấp hơn.

Chuỗi tồn tại vĩ đại là một cấu trúc có thứ bậc của mọi vật chất.
Chuỗi tồn tại phân loại tất cả mọi thứ. Năm mươi năm trước, người ta cho rằng số lượng DNA trong bộ gene cũng có khả năng xếp hạng các sinh vật từ trên xuống dưới như cách mà chuỗi tồn tại phân loại mọi thứ.
Ý tưởng là loài càng phức tạp thì càng cần nhiều gene. Tức là, số lượng gene trong bộ gene nên được sắp xếp từ ít đến nhiều như nấm men, giun tròn, ruồi, và người. Dữ liệu thu được thông qua công nghệ giải trình tự thời đó dường như đã xác nhận ban đầu ý tưởng này.

Khoảng giá trị C của các loài khác nhau không phải là một mối quan hệ gia tăng đơn giản.
Nhưng dần dần, mọi người nhận thấy luồng suy nghĩ này không đúng lắm.
Khi ngày càng có nhiều kết quả giải trình tự cũng như sự tách rời hoàn toàn của hàm lượng DNA và độ phức tạp của sinh vật đã được chứng minh nhiều lần: Giá trị C (diễn tả kích thước bộ gene của một loài) giữa các loài là rất khác nhau. Khoảng giá trị C của các loài khác nhau không phải là một mối quan hệ gia tăng đơn giản và có sự khác biệt rất lớn trong mỗi loài.
Ở động vật, chúng khác nhau hơn 3.300 lần. Ở cây trồng trên cạn, chúng khác nhau khoảng 1000. Dữ liệu cho thấy phạm vi kích thước DNA của nhiều quần thể có thể thay đổi theo một số bậc của độ lớn. Mức độ phức tạp từ tảo đến động vật có vú không tương quan thuận với kích thước bộ gene.
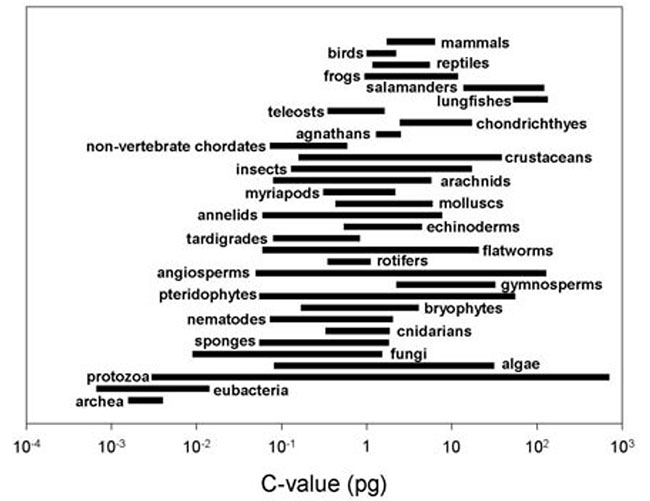
Phạm vi kích thước DNA của nhiều quần thể có thể thay đổi theo một số bậc của độ lớn.
Năm 1971, CA Thomas mô tả vấn đề hóc búa này là nghịch lý giá trị C, thường được mô tả từ ba quan điểm khác nhau sau:
- (1) Một số sinh vật đơn giản có nhiều ADN hơn những sinh vật phức tạp. Một số sinh vật tương đối nguyên thủy, chẳng hạn như động vật chân bụng, có giá trị C cao hơn động vật có vú. Một con amip có số lượng DNA trên mỗi tế bào nhiều hơn 200 lần so với con người. Động vật lưỡng cư, một số loài có bộ gene lớn gấp 25 lần bộ gene của con người.
- (2) Bộ gene của bất kỳ sinh vật nhất định nào dường như chứa nhiều hơn số lượng gene dự đoán của nó, tức là bộ gene có thể chứa một số lượng lớn các đoạn DNA ngoài các gene và trình tự điều hòa của chúng.
- (3) Một số nhóm giống nhau về hình thái thể hiện hàm lượng ADN có tính chất phân hóa cao. Điều này đặc biệt phổ biến ở thực vật, chẳng hạn như lúa (Oryza), lúa miến hoặc hành tây (Allium), chúng khác nhau về kích thước bộ gene đơn bội theo hệ số từ 3 đến 8 lần. Không giống như các gene và trình tự quy định mà chúng ta mong đợi thường tiến hóa chậm và được bảo tồn, vì một số lý do mà kích thước của bộ gene có thể thay đổi nhanh chóng theo khoảng thời gian tiến hóa, như trong trường hợp của bộ gene của ngô (Zea mays) trong khoảng thời gian 140.000 năm, nó đã mở rộng khoảng 50%.
Vài năm sau khi thuật ngữ C-value được đặt ra, việc phát hiện ra một lượng lớn DNA không mã hóa đã giải thích cho vấn đề thứ hai. Những gene không mã hóa này trong những ngày đầu tiên được gọi là DNA rác vì lúc đó người ta cho rằng nó không có tác dụng gì cả. Trong những năm gần đây, người ta đã phát hiện ra rằng DNA không mã hóa có những chức năng quan trọng. Tuy nhiên, sẽ có một bài viết riêng tập trung vào chủ đề này.
Các gene không mã hóa có thể giải thích vấn đề thứ hai, nhưng điều này lại tạo ra những vấn đề mới. gene mã hóa và gene không mã hóa cái nào đóng góp nhiều hơn vào sự phức tạp sinh học? Các gene mã hóa có tương quan với độ phức tạp sinh học sau khi loại bỏ các gene mã hóa dường như không có chức năng không?
Nghịch lý giá trị G
Dự án Bộ gene người (HGP) chính thức được khởi động vào năm 1990. Mục tiêu ban đầu của HGP không chỉ là phát hiện tất cả 3 tỷ cặp gene cơ bản của người với tỷ lệ sai sót nhỏ nhất, mà còn xác nhận từ một lượng lớn dữ liệu được liệt kê - tất cả các gene và trình tự của chúng.
Ngày nay, trình tự DNA của con người được lưu trữ trong cơ sở dữ liệu mà bất kỳ ai cũng có thể tải xuống thông qua Internet.

Các đoạn ADN mang thông tin di truyền được gọi là gene và là các đoạn ADN có thể mã hóa, chúng có thể mã hóa ARN hoặc protein. Vào mùa xuân năm 2000, các nhà sinh học phân tử bắt đầu đặt cược, cố gắng dự đoán số lượng gene có thể được tìm thấy sau khi trình tự nucleotide DNA trong bộ gene người được hoàn thành.
Vào ngày 14 tháng 4 năm 2003, Viện Nghiên cứu Bộ gene Người Quốc gia (NHGRI), Bộ Năng lượng Hoa Kỳ (DOE), và các đối tác của họ trong Hiệp hội Giải trình tự Bộ gene Người Quốc tế đã thông báo về việc hoàn thành thành công Dự án Bộ gene Người. Sử dụng dữ liệu từ HGP, các nhà khoa học ước tính rằng bộ gene người chứa 20.000 đến 25.000 gene.
Số lượng gene trong bộ gene nên tương quan với độ phức tạp, mong muốn rằng sự phức tạp của các sinh vật có thể được sắp xếp như nấm men, giun tròn, ruồi, con người bị hỏng, đây là phiên bản nâng cấp của nghịch lý giá trị C, và được gọi là Nghịch lý giá trị G
Giả định và thuyết sô-vanh hàm ý trong câu hỏi này, rằng con người phức tạp hơn nhiều so với các sinh vật nhân chuẩn được giải trình tự đầy đủ khác và do đó phải có một bộ gene lớn hơn tương ứng, khó có thể biện minh từ kết quả giải trình tự. Điều thú vị là những người mong muốn có nhiều gene hơn đã không từ bỏ cuộc chiến. Họ tiếp tục xuất bản những câu chuyện hợp lý hóa, cố gắng chứng minh rằng có điều gì đó không ổn.
Tại thời điểm này, đó là một giải pháp tốt để phát minh ra một khái niệm mới, một thước đo thực sự có thể xác định thông tin được mã hóa bởi hệ gene, và giá trị I ra đời. Có nhiều lý thuyết để chứng minh rằng giá trị số G của gene không chứa ít thông tin hơn , chẳng hạn như:
1. Sự kết hợp giữa các gene
Khi số lượng gene trong một sinh vật tăng lên, sự kết hợp của các protein mã hóa có thể hoạt động với nhau để thực hiện các chức năng phức tạp sẽ tăng nhanh hơn. Điều này đúng đối với mạng lưới protein truyền tín hiệu và trao đổi chất. Chỉ cần thêm 100 gene vào bộ gene của chúng ta sẽ tạo ra thêm 3,1 triệu tổ hợp theo cặp.
2. Các chức năng khác trên mỗi gene
Dường như chúng ta mã hóa tỷ lệ protein đa chức năng trong bộ gene của chúng ta cao hơn ở ruồi và giun; nghĩa là, trung bình mỗi protein trong cơ thể chúng ta có nhiều cấu hình sinh hóa độc đáo hơn C. elegans và C. elegans Chức năng. Đây được mô tả như một con dao quân đội Thụy Sĩ.
3. Nối ghép thay thế: từ geneome sang transcriptome
Theo các ước tính tốt nhất hiện có, 59% gene được ghép xen kẽ trong quá trình phiên mã. Nếu chỉ xem xét các biến thể liên kết ảnh hưởng đến vùng mã hóa protein, chúng ta nhận được khoảng 69.000 trình tự protein khác nhau được mã hóa bởi bộ gene của chúng ta. Đây là sự gia tăng số lượng gene hơn 300%. Ngược lại, bộ gene giun chứa một tỷ lệ nhỏ hơn các gene nối xen kẽ, tạo ra tới 25.000 protein.
4. Các biến đổi sau dịch mã: từ transcriptome thành proteome
Sau dịch mã, nhiều lần sửa đổi có thể làm tăng thêm số lượng các protein khác biệt về chức năng được mã hóa bởi một gene duy nhất. Các biến đổi phổ biến bao gồm glycosyl hóa, phân giải protein và phosphoryl hóa. So sánh proteome của người (tổng số protein trong một tế bào) với transcriptome (tổng số các bản sao trong một tế bào), chúng ta có thể ước tính mức độ phổ biến của cơ chế này trong bộ gene của chúng ta.
5. Dư thừa di truyền: lạm phát giá trị G
40% đầy đủ các vị trí trong bộ gene của tuyến trùng là kết quả của sự nhân đôi song song, đó có thể là lý do tại sao nó có giá trị G lớn hơn nhiều so với ruồi giấm. Ở chuột, việc loại bỏ một gene nhân đôi thường không hiệu quả, cho thấy rằng có sự dư thừa thông tin đáng kể giữa các locus được nhân đôi trong hệ gene của động vật có vú, dẫn đến giá trị G tăng lên, nhưng chứa cùng một lượng thông tin.
Những lời giải thích này có thể giải quyết kịp thời nghịch lý giá trị G, tất cả đều cố gắng cung cấp cho chúng ta thêm thông tin về từng gene và chúng ta có thể đánh giá thấp thông tin được mã hóa bởi gene nếu chỉ bằng các con số.
Mặt khác, sự tiến hóa không phải là một mô hình của hiệu quả, và nó đã đi một con đường quanh co dẫn đến các bộ gene cồng kềnh hơn mức mà bản thân sinh vật cần. Nó giống như cỗ máy Rube Goldberg: "Có thể có một cách đơn giản để mã hóa cơ thể và hành vi của chúng ta hơn những gì thực sự tồn tại trong bộ gene của chúng ta. Việc đếm số lượng gene có thể đánh giá quá cao thông tin được mã hóa bởi các gene đó".
Sự phức tạp của hướng dẫn (gene) và sự phức tạp của sản phẩm (sinh vật) đơn giản là quá phức tạp để hiểu được nguyên nhân và mối tương quan của sự đa dạng bộ gene của một sinh vật, và nó là không đủ để bắt đầu với con người.
Dự án Bộ gene sinh học của Trái Đất (EBP) là một chương trình kéo dài 10 năm nhằm giải trình tự và lập danh mục bộ gene của tất cả các loài sinh vật nhân chuẩn hiện được mô tả trên Trái Đất. Kế hoạch sẽ thiết lập một cơ sở dữ liệu DNA thông tin sinh học mở, và dự án chính thức được khởi động vào ngày 1 tháng 11 năm 2018.
Lần đầu tiên, có thể giải trình tự một cách hiệu quả bộ gene của tất cả các loài đã biết và sử dụng hệ gene để giúp khám phá 80% đến 90% các loài còn lại hiện chưa được khám phá bởi cộng đồng khoa học.
Khám phá
-

Tại sao bình ga lại phát nổ?
-

Tìm ra "siêu Trái đất" chỉ cách chúng ta 6 năm ánh sáng
-

18 năm sau khi vận hành, siêu đập Tam Hiệp đã tích tụ 1,8 tỷ tấn trầm tích: Nguy hiểm chồng nguy hiểm?
-

Mẹo trị nước ăn chân cực nhanh và an toàn
-

Kỳ lạ cô gái 18 tuổi ở Trung Quốc mắc bệnh "luyến ái não"
-

Kali xyanua là gì?
Khám phá khoa học
-

Phát hiện mới cho thấy não người có thể tạo không gian 11 chiều
-
Trên Trái đất vẫn còn các bộ tộc chưa "thoát" khỏi kỳ đồ đá
-
Lý giải 7 hành vi tâm lý về sự hấp dẫn, cho thấy vẻ đẹp không thực sự nằm trong mắt kẻ si tình
-
Nhiếp ảnh gia bỗng thành "siêu năng lực" sau cú sét đánh xuyên người
-
Tìm hiểu quá trình xác chết phân hủy dưới nước
-
Thảm họa có thể từng đẩy con người tới bờ vực tuyệt chủng





Tiêu điểm
-
Kali xyanua là gì?
-
Cúp vàng World Cup và những sự thật có thể bạn chưa biết
-
Mỏ vàng "cô độc" nhất hành tinh: Hàng trăm tấn vàng "nằm yên" không được ai khai thác
-
Lý do Tần Thủy Hoàng không trả lương bổng cao vẫn khiến quân lính "bán mạng" vì mình
-
Những ngọn núi hình kim tự tháp của Trung Quốc làm dấy lên vô số thuyết âm mưu!
-
Bộ tộc sống giữa rừng sâu nhưng biết hết mọi việc diễn ra khắp thế giới
-
Bị thiên thạch đâm trúng, thị trấn Đức chứa 72.000 tấn kim cương







-

Khám phá khoa học
-

Sinh vật học
-

Khảo cổ học
-

Đại dương học
-

Thế giới động vật
-

Khoa học vũ trụ
-

Danh nhân thế giới
-

Ngày tận thế
-

1001 bí ẩn
-

Chinh phục sao Hỏa
-

Kỳ quan thế giới
-

Người ngoài hành tinh - UFO
-

Trắc nghiệm Khoa học
-

Khoa học quân sự
-

Lịch sử
-

Tại sao
-

Địa danh nổi tiếng
-

Hỏi đáp Khoa học
-

Công nghệ mới
-

Khoa học máy tính
-

Phát minh khoa học
-

AI - Trí tuệ nhân tạo
-

Y học - Sức khỏe
-

Môi trường
-

Bệnh Ung thư
-

Ứng dụng khoa học
-

Câu chuyện khoa học
-

Công trình khoa học
-

Sự kiện Khoa học
-

Thư viện ảnh
-

Video